For many modern language assessments, automated scoring plays a major role in assessing spoken English. Yet pronunciation remains one of the hardest features to measure well. Most systems rely on broad indicators like speech recognition confidence, or outdated assumptions about “native-like” speech, offering little insight into how understandable a speaker actually is.
We set out to change that. In a new paper published in Language Learning, we share the development of a pronunciation scoring model built around intelligibility, not imitation. The model draws on linguistic research, aligns with CEFR descriptors, and was trained on thousands of human-rated responses from diverse speakers.
A pronunciation model grounded in real-world use
Pronunciation has historically been hard to define, and even harder to measure. Existing models often use rough proxies for intelligibility or rely on speech recognition confidence without much transparency. Our goal was to build something better: a model that is grounded in linguistic theory, aligns with the CEFR, and is trained on diverse, real test taker responses.
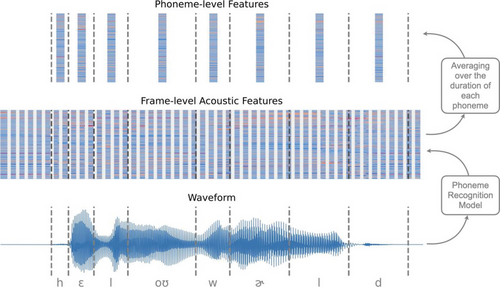
The model evaluates pronunciation across segmental and suprasegmental features. Instead of comparing speech to a L1 accent, it focuses on intelligibility—that is, how easily a test taker can be understood. We trained the model using thousands of human-rated samples and applied modern deep learning techniques to capture nuanced aspects of speech across different levels and backgrounds.
Matching human ratings, outperforming existing systems
The results of the study were clear: our pronunciation model closely predicted expert human ratings. It achieved a Spearman correlation of 0.82, nearly matching the agreement between human raters themselves.
In direct comparisons, it outperformed several state-of-the-art baselines, including Goodness of Pronunciation (GOP), Whisper ASR confidence, and Microsoft’s commercial pronunciation scoring tool.
What set this model apart wasn’t just its accuracy, it was how we built it. Many scoring systems use “black-box” optimization: they train a model to match human scores without clearly defining what the model is learning or why. That approach can yield strong performance, but it also makes the scoring process opaque, and as such, harder to defend in high-stakes contexts.
We took a different path. From the start, we defined pronunciation based on research in applied linguistics, focusing on features that contribute to intelligibility, not imitation of any specific accent. We aligned the training data with CEFR descriptors and ensured our human ratings were grounded in this well-defined construct.
As a result, the model wasn’t just optimized to match scores, it was trained to evaluate the things that actually matter in real-world spoken communication.
Planning for use at scale
Moving from research to real-world deployment requires going beyond model accuracy. In the paper, we identify areas of potential bias—such as lower scores for test takers using Windows devices, likely due to differences in audio quality. We also saw scoring disparities among speakers from certain language families.
To address these issues, we:
- Balanced the training dataset across device types and language backgrounds to reduce demographic and device-related biases.
- Applied data augmentation techniques to simulate diverse acoustic conditions, which helped standardize model performance across varying recording environments.
- Monitored bias metrics during model training and evaluation
- Supplemented the training data with accented speech and estimated scores, helping the model better handle underrepresented language groups and reduce scoring disparities.
We also engineered the system for production: segmenting speech into units that could be scored efficiently, aligning transcripts automatically, and integrating scores seamlessly into our broader speaking assessment pipeline.
Our operational grader employs an extended and updated version of this scoring model that streamlines the original approach and addresses its limitations.
Fairer, faster, and more transparent pronunciation scoring
This publication shows that automatic pronunciation scoring can be transparent, theory-driven, and equitable, without compromising on efficiency or scale. By combining deep learning, human-informed design, and rigorous fairness checks, we’ve built a system that reflects how pronunciation really works in communication.