
In most standardized tests, introducing new content is slow, expensive, and high-risk. New questions typically go through weeks—or months—of standalone pretesting before they’re trusted to influence scores. This makes it hard to keep tests up-to-date, responsive to curriculum changes, or secure against content leaks.
But what if it didn’t have to be that way?
A new system developed by researchers at the Duolingo English Test, and reviewed by our Technical Advisory Board, is changing the rules of the game. Known as S2A3, this framework enables test developers to introduce and score new content immediately—without compromising fairness or validity. And it’s already in use.
Why traditional calibration falls short
Large-scale adaptive tests depend on item banks: vast collections of test questions with carefully estimated difficulty levels. To keep a test fresh and relevant, those item banks must be continuously updated by calibrating the items—that is, estimating the difficulty of each one. But traditional calibration tools simply weren’t built for the pace, nor for the size and complexity, of modern adaptive assessments.
Conventional item calibration software struggles when there are many items and many persons but each person only sees a few of those items, which is typical in adaptive tests. In fact, when the team tested a popular tool for calibration on a dataset with just 100,000 test takers and 20,000 items, it couldn’t complete the task due to memory constraints.
The S2A3 breakthrough: calibrate as you go
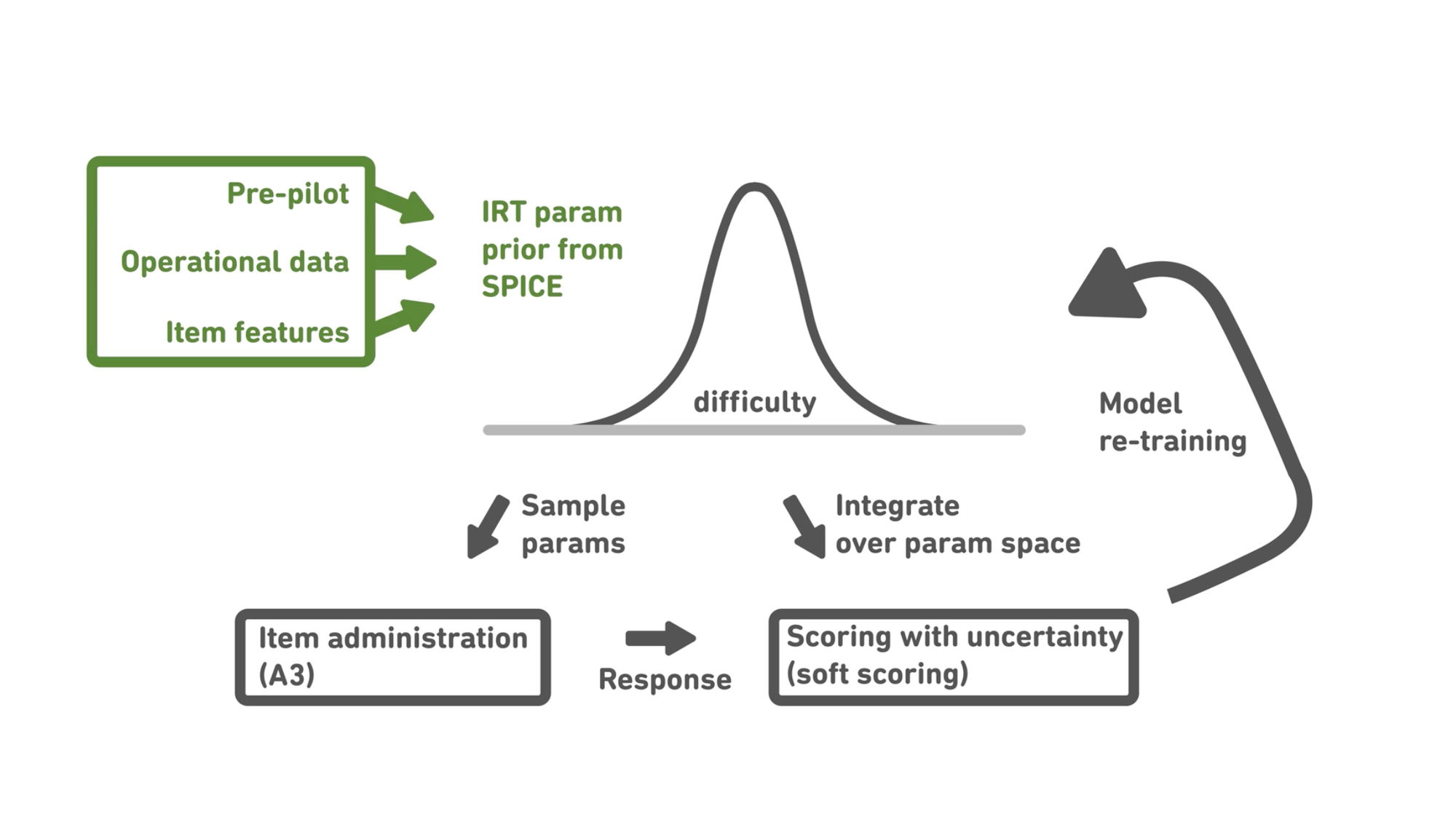
S2A3 sidesteps these limitations by combining three innovations:
- SPICE (Scalable Probabilistic Item Calibration Engine): A Bayesian engine that fuses learner responses with NLP-based item features, enabling fast and flexible calibration—even with limited data.
- S2 (Soft Scoring): A method that reduces the influence of new items, or items with uncertain parameters, on test scores until their parameters are better understood.
- A3 (Adaptive Adaptive Administration): An algorithm that chooses when and how to present new items, optimizing both score precision and calibration speed.
Together, these components enable real-time calibration and continuous item bank expansion.
Scaling up, responsibly
In one experiment, SPICE calibrated over 39 million responses across 100,000 items in under five hours, using standard computing infrastructure. With a smaller dataset of 3.9 million responses, it completed the task in just 33 minutes.
This efficiency has allowed the team to add tens of thousands of new vocabulary items to the DET without traditional pretesting. Items begin contributing to scores right away based on how much we know about them just from their linguistic features—but at reduced weight, with their influence increasing as more data is collected.
To ensure a smooth transition, the S2A3 system was launched gradually, starting with a single item type. Offline validation, live monitoring, and expert oversight helped maintain the validity and comparability of scores throughout the rollout and beyond.
A new model for innovation in assessment
S2A3 demonstrates that rapid test development doesn’t have to come at the cost of fairness or rigor. With the right combination of machine learning, psychometrics, and engineering, it’s possible to create assessments that are both fast-moving and deeply trustworthy.
And as test security, content relevance, and personalization become more urgent priorities in the assessment world, this kind of system may not just be desirable—it may be essential.